新着情報
YOLOv3の利用(1): Mac OS Sierra 環境での転移学習(その1)
Mac はNvidia GPUを使用できず、Deep Learningで時間の掛かる ニューラルネット学習モデルの構築は出来ないと思い込んでいたが、転移学習(Transfer Learning)ならMacでも十分に利用可能と分かった。
転移学習は自前ではなく他者が作成した学習済みモデルを用いて、少数の自前データでも、精度の良い Deep Learning の結果を実現できる。何年か前に、YOLO (You Only Look Onceの略) を利用して画像の認識が簡単に実現できるというインターネットの記事を見て、Mac OSX 環境で写真画像の中の対象物体を検出する事を試し、画像内の対象物を簡単に、精度良く検出することを確認した記憶がある。しかし、ここ数年の間に、計算機ソフトの開発環境の進展が著しく、他環境での学習済みモデルを持ってきても自分の計算機環境で、直ぐに使用できない事が多くなった。最近、YOLOをベースにした学習済みモデルを転移学習に利用して見ようと思い立った。しかし、インターネットでの参考文献(1)の記事を元に勉強を始めたが、記事通りにTerminalにコマンド入力しても、OpenCVに関するエラーが出て先へ進まず、転移学習の落とし穴にハマりまくりであった。
Fig.1は開発環境の不一致による、典型的エラー例である。OpencvのVersion=4.2.0.32では、エラーであるが、Version=4.1.0.25とすればエラーは解消する。
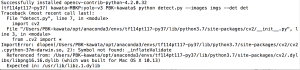
Fig.1. OpenCV_4.2.0.32はMac OS High Sierra(10.13)用であり、現在の私のMac環境OS Sierra(10.12.x)ではOpenCVのバージョンは4.1.x以下でないとfrom cv2 import * が実現できず、 エラーとなる。
私のMacのOS環境はSierra(10.12.6)で、Mac用のAnaconda3-2021.05-MacOSX-x86_64.pkgをインストールしており、仮想環境名 tf114pt170-py37に、 tensorflow_1.14.0 とPyTorch_1.7.0のフレームワークを入れ、画像用のライブラリとして最新のOpenCV version-4.5.5を入れていた。
主なエラー原因は、学習済みモデルは学習を実施したフレーム環境のバージョンや使用した各種ライブラリのバージョンが、転移学習を実施するフレーム環境や各種ライブラリのバージョンが異なる為に、様々なエラーが生じる。エラーメッセージを検索して、試行錯誤により解決する必要がある。今回は、OpenCVのバージョンは4.5 .5から順に4.2.0.32まで落としてもダメで、最終的に4.1.0.25でエラーは出なくなった。
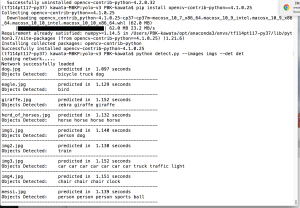
Fig.2. OpenCV_4.1.0.25に下げてpip installする。detect.pyを実行すると今度は正常動作し、フォルダimgs内の複数の画像ファイルを順に画像内の対象物を検知し、対象物をラベル付き枠で囲んだ画像を作成する事ができた。
具体例として、Fig.3-(a) dog-cycle-car.jpg とFig.3-(b)ラベル枠付きの検知処理後の画像det-dog-cycle-car.jpgを下記に示す。しかし、検出領域の枠に検出ラベルが表示されるだけで、検出精度の表示がないので、検出精度の表示も出来る様にプログラムの改善をしたいと思っている。

Fig.3-(a). 処理対象画像。

Fig.3-(b). 検出された認識処理後の画像
文献(2) と文献(3) は大変有益であり、特に恩恵を受けた。
文献(2)でYOLOv3を実現した環境は
- Python 3.5
- OpenCV
- PyTorch 0.4
であると、明記してあるが、Python は、3.6, 3.7, 3.8 ,3.9でもOK。
文献(2)では、PyTorch は1.10でも、 1.7.0でも、 1.8.0でもOK。しかし、Mac OS Sierraでは、OpenCVは4.1.0.25 以下のみOKである。OS High Sierraは4.2.0.32でもOK。その他のMac OSについては試行錯誤していないので不明である。
YOLOv3による学習済みweightsを利用した転移学習の手順は以下の通り。
(1) 画像データ内の対象物認識について:
① Terminal を開き、下記のコマンドを入力して、PCのホーム・ディレクトリ(/home/ユーザー名)の下にgithubウェブ・サイトのクローン・ディレクトリを作成する。
> git clone https://github.com/ayooshkathuria/pytorch-yolo-v3
② 次に、下記のcdコマンドを入力して、サイトのクローン・ディレクトリに入る。
> cd pytorch-yolo-v3
③ YOLOによる学習済みyolov3.weightsファイルを下記のコマンドによりダウンロードする。
> wget https://pjreddie.com/media/files/yolov3.weights
これら上記③のコマンドを入力後、
④ クローン・フォルダ(pytorch-yolo-v3)内のutil.pyファイルに誤りがあるので、
文献(3)で与えられるutil.pyファイルと置換する必要がある。
⑤ util.pyファイルを置換した後、下記のコマンドを実行する。
> python detect.py --images imgs --det det
このコマンドにより、imgsフォルダ内のすべての画像データに対して対象物の検出処理を施した画像データが作成され、フォルダdetに格納される。
(2) ビデオ映像内の対象物認識について:
プログラムvideo_demo.py を次のコマンドで実行することにより、クローン・フォルダ(pytorch-yolo-v3)内に配置したvideo.aviの映像内の対象物の検出がリアルタイムで実施される。
> python video_demo.py --video video.avi (--reso 64)
ビデオ・フォーマットは .avi と.mp4どちらも有効なことを確認した。
(2) Macの内蔵カメラによるリアルタイム映像内の対象物認識について:
> python cam_demo.py (--reso 64)
処理速度が追いつかず、カクカクとした動きになるので、解像度を–reso 64に落とした方が滑らかな映像となり
見易くなる。
参考文献
(1)【Python】YOLOv3を使ってみた
https://qiita.com/konan/items/f29ac144f960d0f6a8ec
(2) A PyTorch implementation of a YOLO v3 Object Detector
https://github.com/ayooshkathuria/pytorch-yolo-v3
(3) pytorch-yolo-v3のRuntimeErrorを解消できたよ
http://kazuki-room.com/i_was_able_to_resolve_the_runtimeerror_of_pytorch-yolo-v3/
(4) このページのファイルutil.pyを
ディレクトリpytorch-yolo-v3/の下にあるファイルutil.pyに置換した後、
https://github.com/ayooshkathuria/pytorch-yolo-v3/blob/3aa94c3fba787ea99e07d0f5c6e2668df0d1baa7/util.py
このutil.pyを置換した後、下記コマンドを実行すると画像内の検知処理は正常終了する。
> python detect.py --images imgs --det det
(5)YOLO: Real Time Object Detection by Joseph Chet Redmon