新着情報
YOLOv3の利用(3):Windows 10 環境での転移学習
Windows 10の環境での転移学習の実現手順について:
YOLOv3の利用(2): UBUNTU20.04 環境で述べた転移学習の実現手順はWindows 10でも変わらず、転移学習は同じ手順で実現できる。 私のWindows 10 Proは自作PC であり、UBUNTU 20.04とWindow 10 Proの起動可能な Dual Boot マシーン である(Processor: AMD Ryzen 7 3700X (8-Core Processor 3.59 GHz)+NVIDIA GeForce RTX 2060)。 ニューラル・ネットワークを実現する代表的な学習環境としてTensorFlow フレームワークと PyTorch フレームワークがある。どのフレームワークでも、既存の学習済み重みを利用して、 異なる新しいデータに適用する転移学習は可能であり、始めから学習するより効率的である。 この転移学習をWindows 10で行う手順について確認する。 このWindows 10 ProはAnacondaの公式サイトより、下記インストーラ Anaconda3-2021.11-Windows-x86_64.exe をダウンロードし、Anaconda3をインストール済みである。 更に、Anaconda-navigator を利用して、2つのPython仮想環境( tf2p37 )と(pt110p37)を既に作成してある。
(1) TensorFlow ver.2フレームワーク下でYOLOv3による転移学習を実現する手順:
TensorFlow-ver.2.0フレームワーク用のソフトを仮想環境( tf2p37 )に導入し、 YOLOv3による転移学習を実現する手順を確認する
① Python仮想環境(tf2p37)をactivateする。
②次に、このサイト(https://github.com/zzh8829/yolov3-tf2)に、アクセスしてホーム・ページの緑色の[Code]をクリックして、Download ZIPファイルをダウンロードする。ダウンロード後、自分のホーム(C:¥Users¥ユーザー名)下に展開して、ディレクトリ名yolov3-tf2-masterができるが、yolov3-tf251gpuと改名する。ここでは、便宜上、ホーム直下のファイルの配置箱をディレクトリとよび、その内部のファイルを配置箱はフォルダと呼ぶことにする。
上記のgithubサイトは git clone コマンドによる一般ユーザーによるクローン化を受付けないので、
ダウンロードしたDownloadZIPファイルを自分のホーム直下に展開する。展開してできるディレクトリ名を
yolov3-tf251gpuと改名する。
③まず、Powershell Terminalを開き、下記のcdコマンドを入力してカレント・ディレクトリを yolov3-tf251gpu ディレクトリに移動する。
(tf2p37) PS C:¥Users¥ykmsf> cd yolo3-tf251gpu
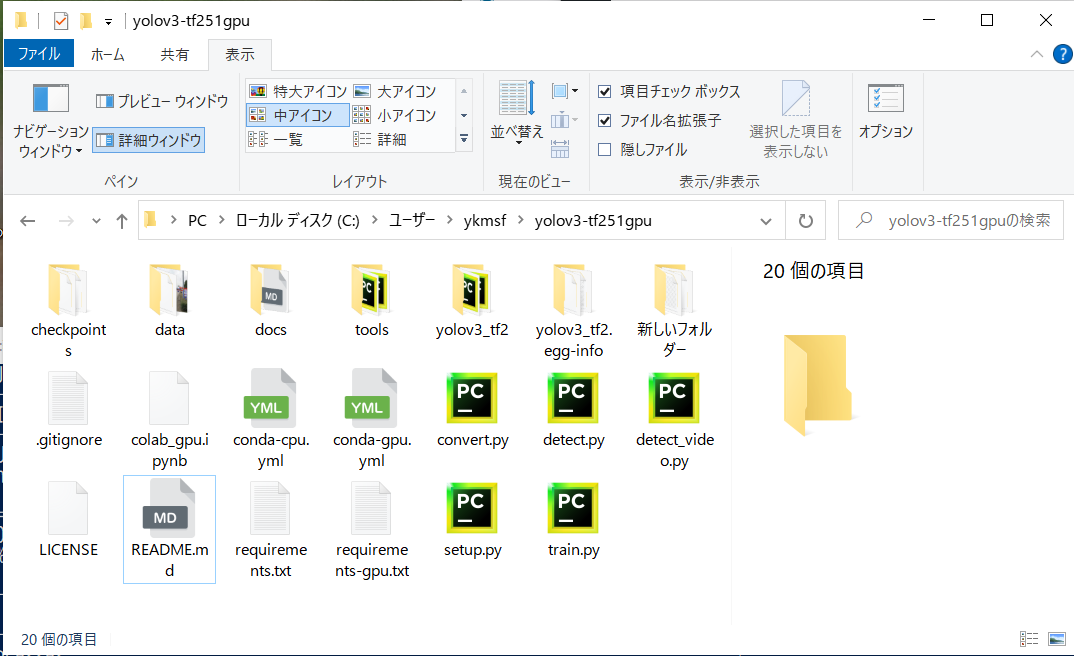
Fig.1. ディレクトリyolov3-tf251gpuの内部。 https://github.com/zzh8829/yolov3-tf2のクローンとなっている。
④ yolov3の学習済みモデルと同じpython環境を一括インストールするrequirements.txtファイルを以下のpip installコマンドで実行する。ディレクトリyolov3-tf251gpu内には 2つの requirements.txtファイルが存在している。 即ち、requirements.txtとrequirements-gpu.txt の2つのファイルである。 Terminalのホーム(tf2p37) PS C:¥Users¥ykmsfまでの文字列部分が長くなるので、簡単の為、~で代用することにする。
(a) CPUだけの場合、
~¥ yolov3-tf251gpu> pip install -r reqirements.txt
(b) GPUが利用できる場合、
~¥yolov3-tf251gpu> pip install -r reqirements-gpu.txt この
Windows 10 ProではGPUを使用する為のCUDA及びcuDNNの設定は完了しており、(b)のコマンドを実行した。
⑤ 次に、学習済みのyolov3.weightファイルのダウンロードを以下のサイトから行う。
https://pjreddie.com/media/files/yolov3.weights
ダウンロードしたyolov3.weightsファイルはフォルダyolov3-tf251gpu内のweightフォルダ内に配置する必要がある。
⑥ ダウンロードした yolov3.weightsファイルを下記のconvert.pyコマンドによりkerasモデル用に学習重みづけの変換を行う。
~¥yolov3-tf251gpu> python convert.py – -weights data/yolov3.weights – -output checkpoints/yolov3.tf
このコマンドはUbuntu 20.04では、エラーなく進むが、Windows 10 Proでは、zlibwapi.dllの所在場所が不明としてpythonの実行が停止するエラーが生じた。
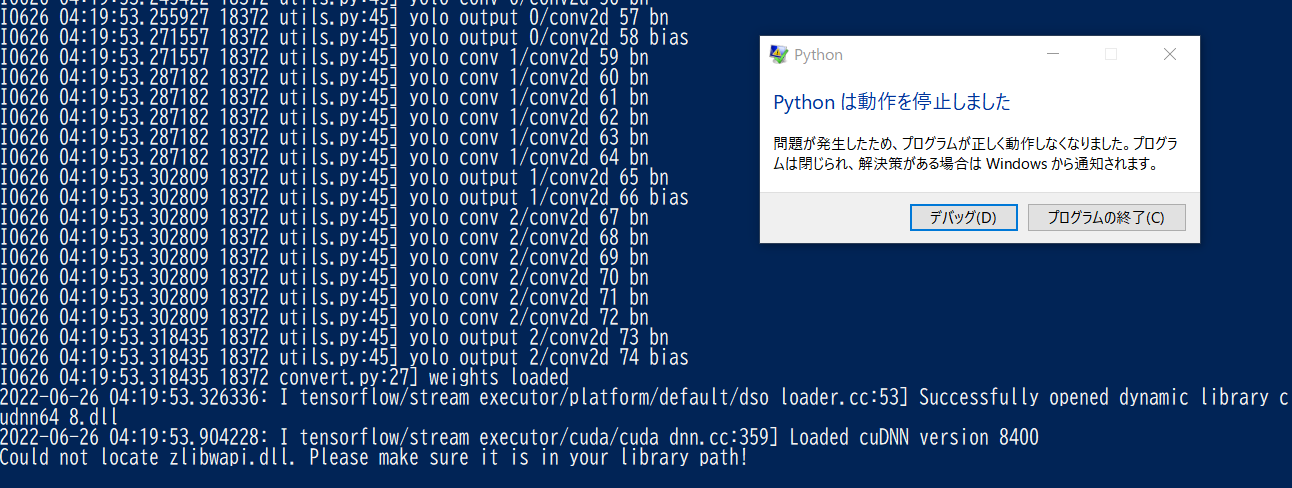
Fig.2. PowerShell TerminalにてPython実行がzlibwapi.dllの所在不明で停止する。
この謎のダイナミック・ライブラリzlibwapi.dllの所在場所が不明で、謎の解明ができずに悩んだが、
Windows の虫眼鏡アイコンで所在を探したら、 C:¥Users¥ykmsf¥anaconda3¥envs¥tor113tf26¥Lib¥site-packages¥torch¥lib¥zlibwapi.dll にあった。このダイナミック・ライブラリzlibwapi.dllが何をするファイルなのか未だに分からないが、とにかく これをコピーし、yolov3-tf251gpuディレクトリ内に貼り付けて ⑤のpython convert.pyコマンドを再実行したら、今度はエラー無く正常終了した。終了後、checkpoint フォルダ内に、checkpointとyolov3.tf.data-00000-of-00001及びyolov3.tf.indexの3個のファイルが作成できていた。
⑥ 次に、Fig.1 に示す画像データstreet.jpgをdataフォルダに配置し、

Fig.1. Street.jpgの表示。
下記のpython detect.pyコマンドを実行すると、
~¥yolov3-tf2-master> python detect.py – -image data/street.jpg 正常終了できた。
即ち、ディレクトリyolov3-tf251gpu内に、画像データstreet.jpg内の対象物の検出領域、枠ラベルと検出精度等が付いた処理済みの画像データoutput.jpg が作成されていた(Fig.2.参照)。

Fig.2. 対象物検出処理済み画像output.jpg。
⑦ ビデオ映像内の対象物検出の場合: (a) サンプルビデオcars.mp4をdataフォルダ内に配置し、下記の
python detect_video.pyコマンドの実行により、対象物検出処理済み映像 moving-cars.aviを制作できる。
~¥yolov3-tf251gpu> python detect_video.py – -video data/cars.mp4 – -output moving-cars.avi
OpenCVは、codec = cv2.VideoWriter_fourcc(*’XVID‘)をサポートするので、aviファイルの書き込み出力ができるが、しかし、著作権の関係でmp4を書き出すコーデックcodec=cv2.VideoWriter_fourcc(*’MP4V‘)や codec=cv2.VideoWriter_fourcc(*’H264‘)をサポートをしない。
その為、OpenCVでは、mp4ファイルの書き込みはできず、mp4の作成を試みても失敗する。 しかし、Ciscoが版権を持ち、オープン使用が許可されているバイナリ・ファイルopenh264-1.8.0-win64.dllをdetect_video.pyプログラムと同じフォルダに配置すれば、OpenCVのcodec=cv2.VideoWrighter_fourcc(*’H264‘)はサポートされ、警告・メッセージは出るが、無償でmp4ファイルの作成が可能となることが分かった(参考文献(3)を参照)。
Fig.3. 対象物検出済みビデオ映像。作成したmoving-cars.mp4はWordPressに直接埋み可能である。
⑧ カメラ映像内の対象物検出の場合: (a)下記コマンド実行により、USBカメラによるリアルタイム映像に対し、直ちに対象物の検出処理済み映像を
output.aviとして、書き込み制作できる。
~/yolov3-tf251gpu> python detect_video.py – -video 0
– -output output.avi
(b) 内蔵cam映像の検出処理済み映像をoutput.mp4として、書き込み制作する場合は、
detect_video.pyでcodec=cv2.VideoWriter_fourcc(*’H264‘)と変更し、下記コマンドを実行すれば良い。
~/yolov3-tf251gpu> python detect_video.py – -video 0
– -output output.mp4
なお、- -video の後ろの0は番号ゼロであり、計算機の内蔵cameraを意味する。
いずれの場合も、計算にはNvidia GPUを使用しており、Windows 10 Proにおける転移学習の高速処理の実現を 確認できた。また、Windows 10ではaviファイルの作成だけでなく、 openh264-1.8.0-win64.dllをプログラムと同じディレクトリに配置すれば、 直接的にmp4ファイルの作成が出来ることを確認した。
(2) PyTorchフレームワーク下でYOLOv3による転移学習を実現する手順:
参考にしたサイトは参考文献(2)で紹介するサイトである。
PyTorchフレームワーク用のソフトをPython仮想環境(pt110p37)に導入してYOLOv3による転移学習の実現を行う。
今回、サイト(参考文献(2))の手順通りの作業で、Windows 10環境で転移学習の再現ができるか試みる。
① まず、Python仮想環境(pt110p37)を activate する。この仮想環境のPythonのバージョンは3.7であり、Torch==1.11.0+cu113 Torchvision==0.12.0+cu113
Torchaudio== 0.11.0+cu113がインストール済みである。
その後、ターミナルを立ち上げ、そのホームデレクトリにて、下記の git clone コマンドを実行する。
ここでは、Terminal上でホームやカレント・ディレクトリまでの文字列が長くなるので、簡単の為、> で代表させる。
> git clone https://github.com/nekobean/pytorch_yolov3.git
次に、以下の cd コマンドにより、カレント・デレクトリをpytorch_yulov3に移動する。
> cd pytorch_yolov3
②このクローン・ディレクトリpytorch_yolov3には requirements.txtファイルが存在しており、下記コマンドの実行により、転移学習をするPythonライブラリ環境をyolov3の学習済みモデルのPythonライブラリ環境と合わせることができる。 > pip install -r requirements.txt ③UBUNTUでは、bashが使用でき、下記のコマンドをターミナルで実行すれば、MS COCOの学習時の重みファイルをダウンロードできる。
./weights/download_weights.sh
yolov3.weights: MSCOCO で学習した YOLOv3 の重みファイルyolov3-tiny.weights: MSCOCO で学習した YOLOv3-tiny の重みファイル- darknet53.conv.74: YOLOで学習開始時に使う初期のウェイトファイルで、YOLOv3の重みファイルとは別ファイルであり、転移学習では使用しない
しかし、Windowsでは ブラウザに直接URLを入れ、リターンキーを押すと、 https://pjreddie.com/media/files/yolov3.weights
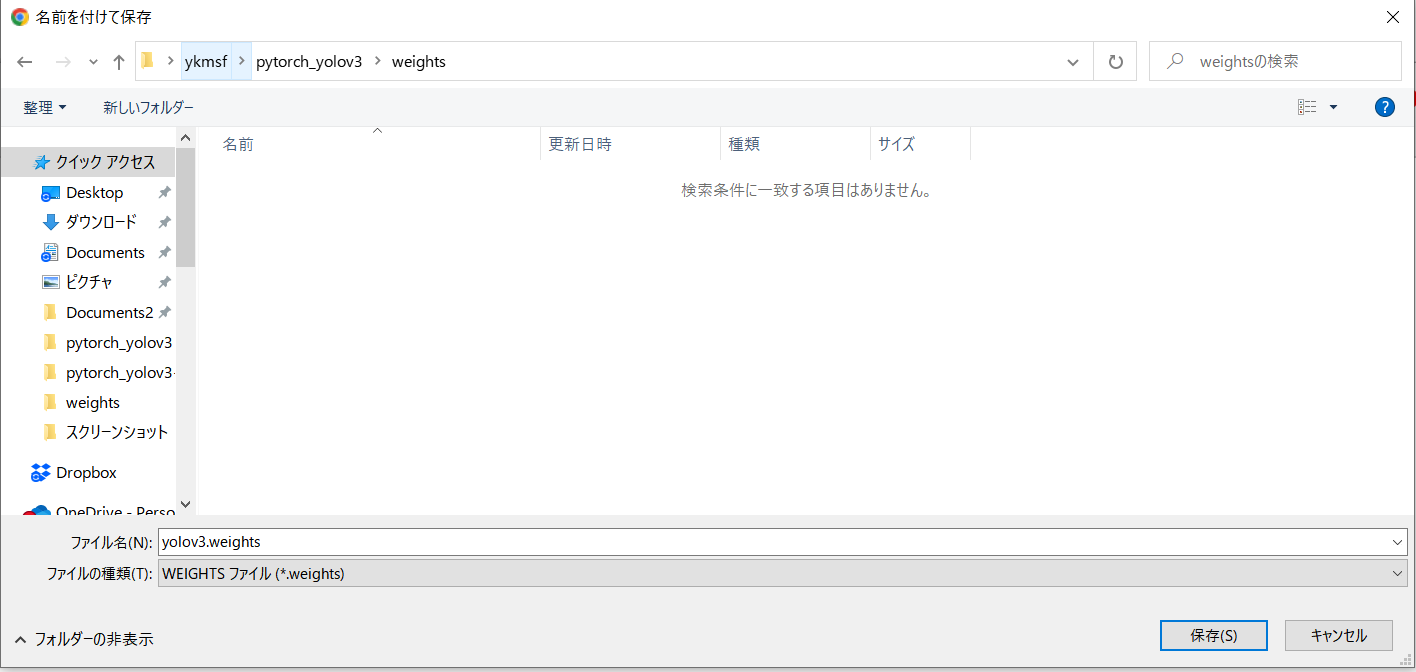
Fig.4. yolov3.weightsの保存名と保存先の設定画面になるので、 ykmsf¥pytorch_yolov3¥weightsフォルダ内に設定して保存する。
保存ファイル名や保存先の設定画面が出るので、weightsフォルダ内にダウンロード配置する。 少ないパラメータ数による学習済みファイルyolov3-tiny.weightsのダウンロードも同様にブラウザに
下記のURLを入力して、weightsフォルダ内にダウンロード配置する。
https://pjreddie.com/media/files/yolov3-tiny.weights
MS(MicroSoft) COCO の学習済みモデルについて:
yolov3.weights 及び yolov3-tiny.weightsは、以下の80クラスを含む約10万枚の画像で構成される画像データセットで
学習した重みファイルである。 この80クラスの対象物を検出する場合は、yolov3の学習済みモデルを利用すれば、
新しい画像や映像に対しても、すぐに検出を行うことが可能である。
| クラス ID | クラス名 | クラス ID | クラス名 | クラス ID | クラス名 | クラス ID | クラス名 |
|---|---|---|---|---|---|---|---|
| 0 | 人 | 20 | ゾウ | 40 | ワイングラス | 60 | ダイニングテーブル |
| 1 | 自転車 | 21 | クマ | 41 | カップ | 61 | トイレ |
| 2 | 車 | 22 | シマウマ | 42 | フォーク | 62 | テレビ |
| 3 | バイク | 23 | キリン | 43 | ナイフ | 63 | ノートパソコン |
| 4 | 飛行機 | 24 | リュックサック | 44 | スプーン | 64 | マウス |
| 5 | バス | 25 | 傘 | 45 | ボウル | 65 | リモコン |
| 6 | 電車 | 26 | ハンドバッグ | 46 | バナナ | 66 | キーボード |
| 7 | トラック | 27 | ネクタイ | 47 | リンゴ | 67 | 携帯電話 |
| 8 | 船 | 28 | スーツケース | 48 | サンドウィッチ | 68 | 電子レンジ |
| 9 | 信号機 | 29 | フリスビー | 49 | オレンジ | 69 | オーブン |
| 10 | 消火栓 | 30 | スキー | 50 | ブロッコリー | 70 | トースター |
| 11 | ストップサイン | 31 | スノーボード | 51 | キャロット | 71 | シンク |
| 12 | パーキングメーター | 32 | スポーツボール | 52 | ホットドッグ | 72 | 冷蔵庫 |
| 13 | ベンチ | 33 | カイト | 53 | ピザ | 73 | 本 |
| 14 | 鳥 | 34 | 野球バット | 54 | ドーナツ | 74 | 時計 |
| 15 | 猫 | 35 | 野球グラブ | 55 | ケーキ | 75 | 花瓶 |
| 16 | 犬 | 36 | スケートボード | 56 | 椅子 | 76 | ハサミ |
| 17 | 馬 | 37 | サーフボード | 57 | ソファー | 77 | テディベア |
| 18 | 羊 | 38 | テニスラケット | 58 | 鉢植え | 78 | ヘアードライヤー |
| 19 | 牛 | 39 | ボトル | 59 | ベッド | 79 | 歯ブラシ |
Table 1. MS COCOの80クラス検出カテゴリ(表の作成は参考文献(2)による)。
③ フォルダdataに単一画像person.pngを配置し、検出処理済み画像をoutputフォルダに出力する場合:
> python detect_image.py –input data/person.png – -output output – -weights weights/yolov3.weights – -config config/yolov3_coco.yaml

Fig.5. person.png画像の表示。

Fig. 6. person.png画像内の対象物の検出処理済み画像である。犬、人、馬が検出され、検出領域、検出ラベルと検出精度も表示されている。
④ dataフォルダに複数の画像を配置し、複数の検出処理画像をoutputフォルダに出力する場合:
下記のpython detect_image.pyコマンドを実行する。
python detect_image.py – -input data – -output output
– -weights weights/yolov3.weights – -config config/yolov3_coco.yaml
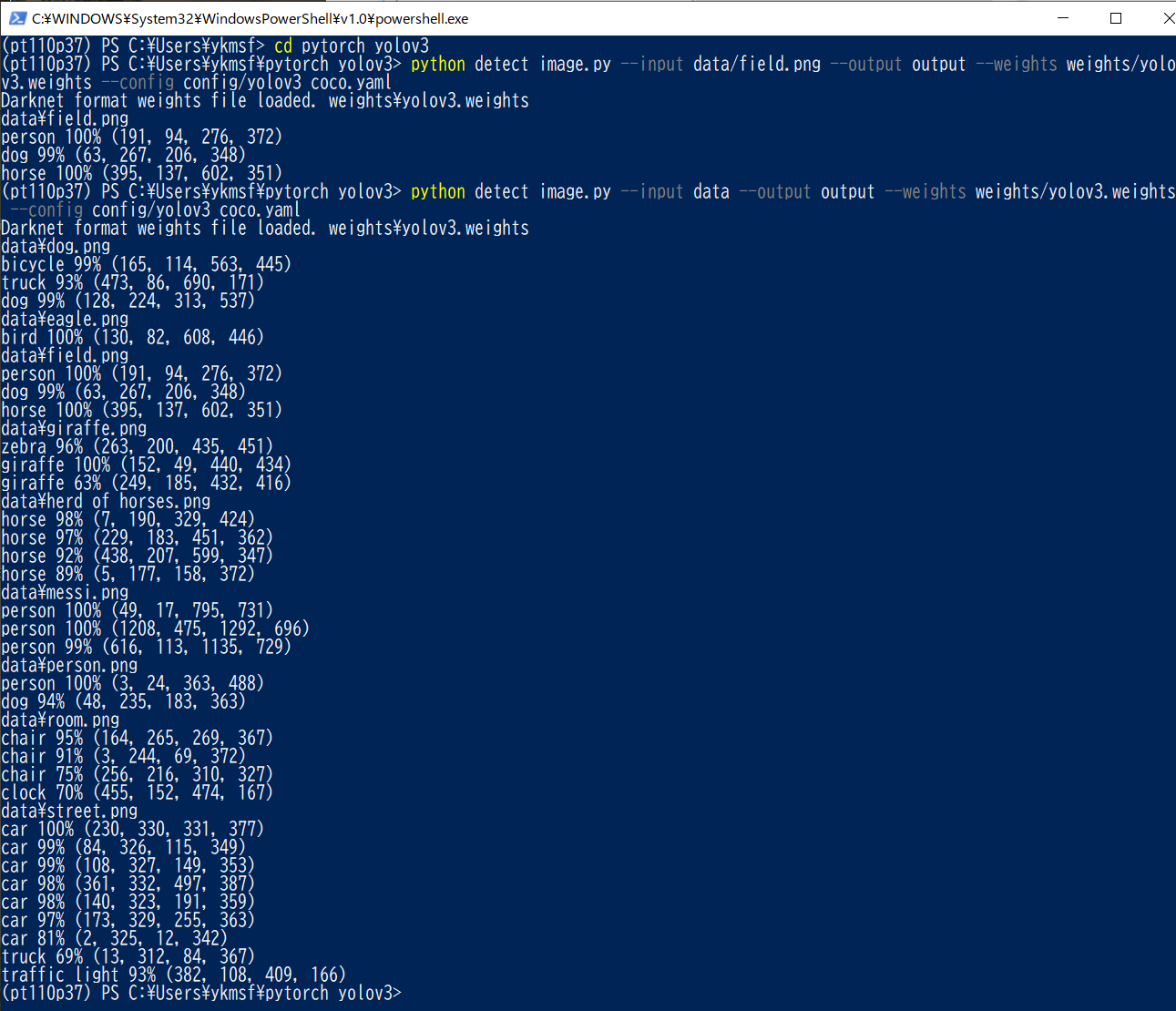
Fig.7. 複数の入力画像に対し、検出処理を順次実施する実行画面む。各対象物のラベル、検出領域の右上と左下の座標位置と検出精度の計算が実施されている。
⑤フォルダdataにビデオ映像sample.aviを配置して、gpu使用を指定し、高速に検出済み映像をoutputフォルダに書き込む場合:
高速処理のため、yolov3-tiny.weightsとyolov3tiny_coco.yamlを使用し、且つ、gpu_id として0 番を指定している。gpuが1個の場合、その装置番号は0番となる。
> python detect_video.py – -input data/sample.avi – -output output – -weights weights/yolov3-tiny.weights – -config config/yolov3tiny_coco.yaml –gpu_id 0
この場合の対象物検出済み映像名はoutputフォルダ内にsample.aviとして書き出される。
これをprocessedフォルダ内にprocessed.mp4として書き出すには、detect_video.py
プログラムに次の2カ所を変える必要がある。
(a) detect_video.py の49行目のaviをmp4に換える。
49行目をコメントアウトし、50行目を追加する。
49 # output_path = args.output / f”{args.input.stem}.avi”
50 output_path = args.output / f”{args.output.stem}.mp4”
(b) detect_video.pyの60行目と61行目をコメントアウトし、62行目を追加する。
60 # fourcc = cv2.VideoWriter_fourcc(*”DIVX“)
61 # fourcc = cv2.VideoWriter_fourcc(*”H264“)
62 fourcc = cv2.VideoWriter_fourcc(*”avc1“)
62行目をコメントアウトし、61行目の#を消して、detect_video.pyを実行すると、mp4ファイルは出力されるが、コーディック”H264″に関してffmpegからの警告文がTerminalに出力される。(b)に従うと、警告文の出力もなく、mp4ファイルは書き込み出力され、完全な正常終了となった。
上記の改変を実施し、且つ、バイナリー・ファイルopenh264-1.8.0-win64.dllをdetect_video.pyの存在するpytoch_yolov3デレクトリーに配置して、下記のコマンド
> python detect_video.py – -input data/sample.avi – -output processed – -weights weights/yolov3-tiny.weights – -config config/yolov3tiny_coco.yaml – -gpu_id 0
を実行すれば、processed.mp4の出力ができる。
Fig.8の検出結果は、yolov3-tiny.weightsのパラメータ数の少ないweightsを使用したため、処理時間の短縮はできたが、枠領域が小さくpersonの半分程度の領域になった。通常のyolov3.weightsを使用した時は検出の枠領域はほぼperson全域を覆っており、検出の精度も高かった。
Fig.8. 対象検出済み映像processed.mp4。
以上、Windows 10 Pro環境における転移学習の実現手順を確認したが、zlibwapi.dllの所在不明によるエラーを除いては順調だった。zlibwapi.dll問題について何か知見のある人からのコメントを希望します。